
Introduction
Machine learning transforms the way organizations look at customer behavior. The analysis in this article offers a direct but strategic version of a relatively simple technique: the decision tree. Based on anonymous customer data from a webshop, we trained a model with approximately 4,000 customers. This model reveals that with only two factors: the customer complaint score and the customer loyalty score. The spending behavior of customer purchases (low, mid, high) could be predicted with reasonable accuracy.
The reliability and predictive power of the model are directly linked to the machine learning methodology for decision trees:
1. Thorough Data Preparation: Before the model could learn, essential pre-processing steps were necessary:
- Defining a clear Target Variable (spending category of low, mid, & high values).
- Removing unusable data (customer IDs) and noise.
- Correctly setting Data Types (numerical versus categorical) for the decision tree to function optimally.
2. Robust Validation: The dataset was split into a Training Set (80%) and an independent Test Set (20%). This prevents overfitting, which is the risk that the model only learns patterns in the training data. By generating a test set, the model guarantees a more realistic view of how well the model can predict new customers.
Strategic insights from the decision tree:
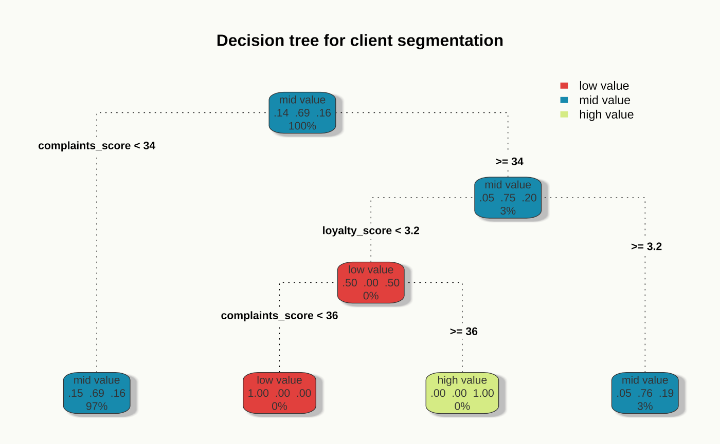
The interpretation of the decision tree offers marketers and service teams immediately usable insights:
- Complaints as an important independent variable: The complaint score appears to be the strongest predictor. Customers with a low complaint score below 34% almost always fall into the mid-segment (69% of the total number of customers). But even with a complaint score above 34%, there is still a 75% chance of ending up in the mid-segment. This demonstrates that basic satisfaction (few complaints) is reasonable for maintaining the bulk of the revenue.
- Loyalty also seen as an independent variable: In the smaller, heterogeneous group with a high complaint score, the loyalty score provides more finesse to the model:
- Low loyalty: Pushes customers towards the two extreme segments (low or high spenders). High spenders arise almost exclusively within the specific combination of many complaints and low loyalty. This is therefore a target group that deems high spending necessary, which makes the customer relationship valuable but also fragile.
- High loyalty: Has an offsetting effect on the negative influence of complaints and more often keeps customers in the mid-segment.
Evaluation and performance of the model
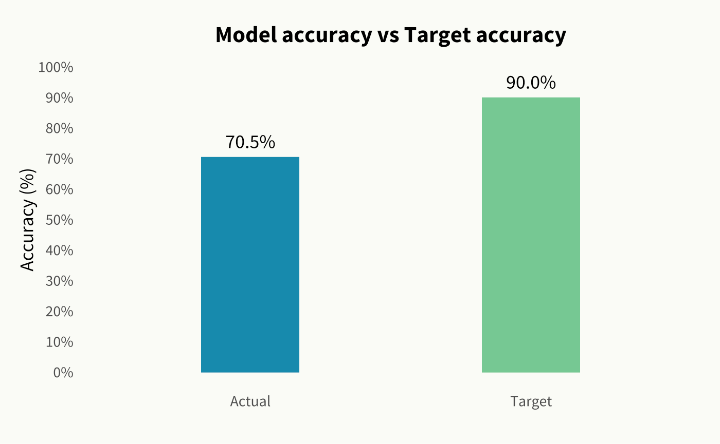
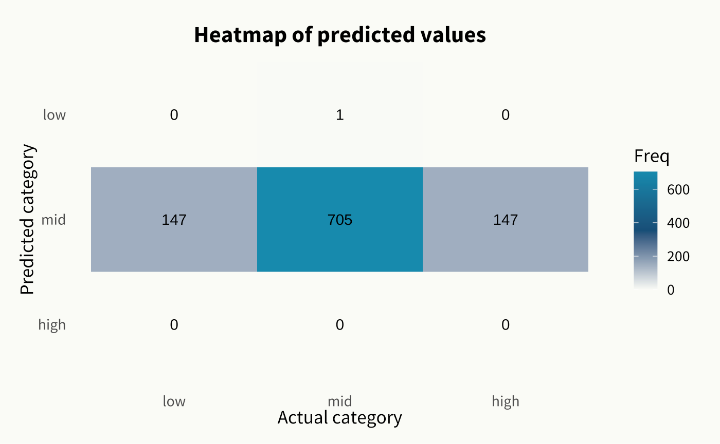
The model achieved an initial Accuracy Score of 70.5%, which is a solid starting point. However, the Confusion Matrix revealed that the model almost exclusively gravitates toward the mid-segment, often missing the extreme segments (low and high spenders).
"
"
This underlines the importance of:
- Model inspection and validation: Blind trust in the first model version is risky. The evaluation is crucial to see which segments are still insufficiently distinguished.
- Iterative improvement: The next step is Feature Engineering. This is a smarter enrichment and reconstruction of variables to increase the distinguishing power and bring the accuracy towards a target of 90%.
This model provides direct insights for retention plans (high-spenders with low loyalty), preventative service flows (mid-spenders with increasing complaints), and increasing conversion through targeted upsell actions.
Conclusion
The conclusion is clear: Complaints determined the main direction in this dataset. Loyalty pays off in an offsetting effect at customer with a high complaint score.
